
What We Learned Building O11y GPT: Part II
 By Observe Team May 15, 2023
By Observe Team May 15, 2023
We’re genuinely excited, as it appears we’re at the very beginning of a new way of helping engineers and other observability users around the world!
In our previous post, we talked about how we use embeddings and a similarity index to find the most relevant pieces from Observe’s documentation to help answer user questions. This approach worked okay when we tested it, but to get from “okay” to “good” we had to augment it in four ways.
Fine-Tuning O11y GPT
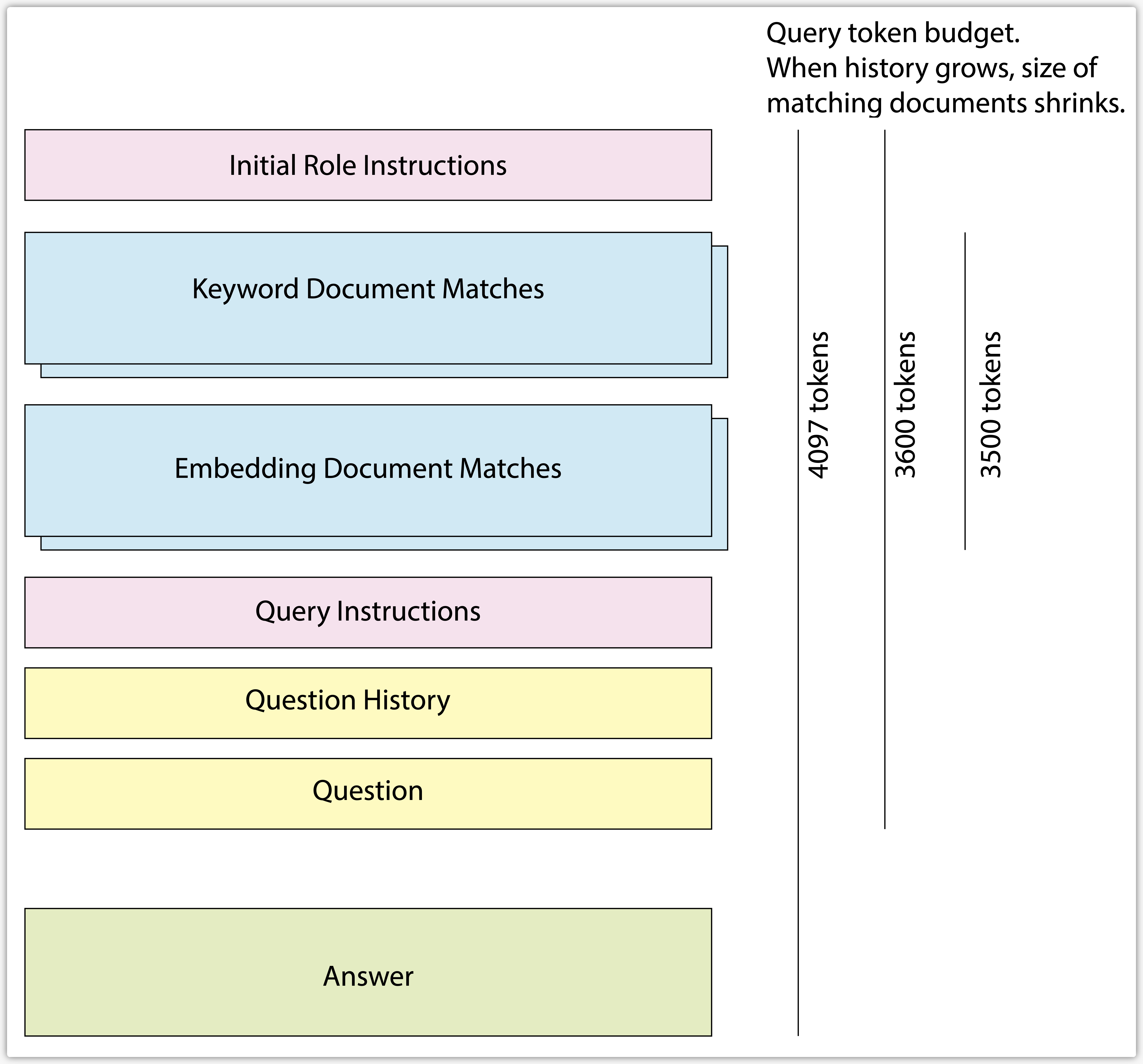
First, we identify questions related to our query language, OPAL. When the text “OPAL” or any of its verbs or functions are mentioned, we make sure to include a description of the OPAL language grammar and the help page for the specific operator. This ensures that O11y focuses on relevant information rather than, for example, semi-precious stones. Combining keyword matching and embeddings strikes a good balance, as keyword matching effectively locates specific documentation, while embeddings help find related documents. By blending these techniques, we generate the optimal 3000 words corpus to prime the model for answering a question.

The second enhancement involves creating a prompt that adds focusing instructions to the query. Providing the model with a role, offering examples, and defining boundaries for discussion prove helpful. Additionally, specifying how the model should respond when a question strays beyond its scope is beneficial. For instance, if O11y responds with “That does not compute,” it indicates the query is unrelated to observability, as predicted by the model.
The third enhancement involves providing context-specific history. We input each previous question from the chat into the model, enabling it to maintain the thread in a conversation that refers back to earlier information. This technique resembles the ChatGPT web product itself, as the model itself lacks memory and “just” predicts outputs based on given inputs. Due to space constraints, we don’t include previous answer text in the prompt, but the model still performs well given only questions, possibly because it can internally refer to the same answers it would previously have predicted from those questions.
The fourth enhancement involves iteration. This should come as no surprise to anyone who has worked with machine learning models or data analytics — paying attention, and guiding the process, is the sweat equity that builds value. Initially, we implemented a script that asked questions on the command line, helping us quickly iterate on how prompt engineering, context, and embeddings impacted the results.
Internal Use Cases
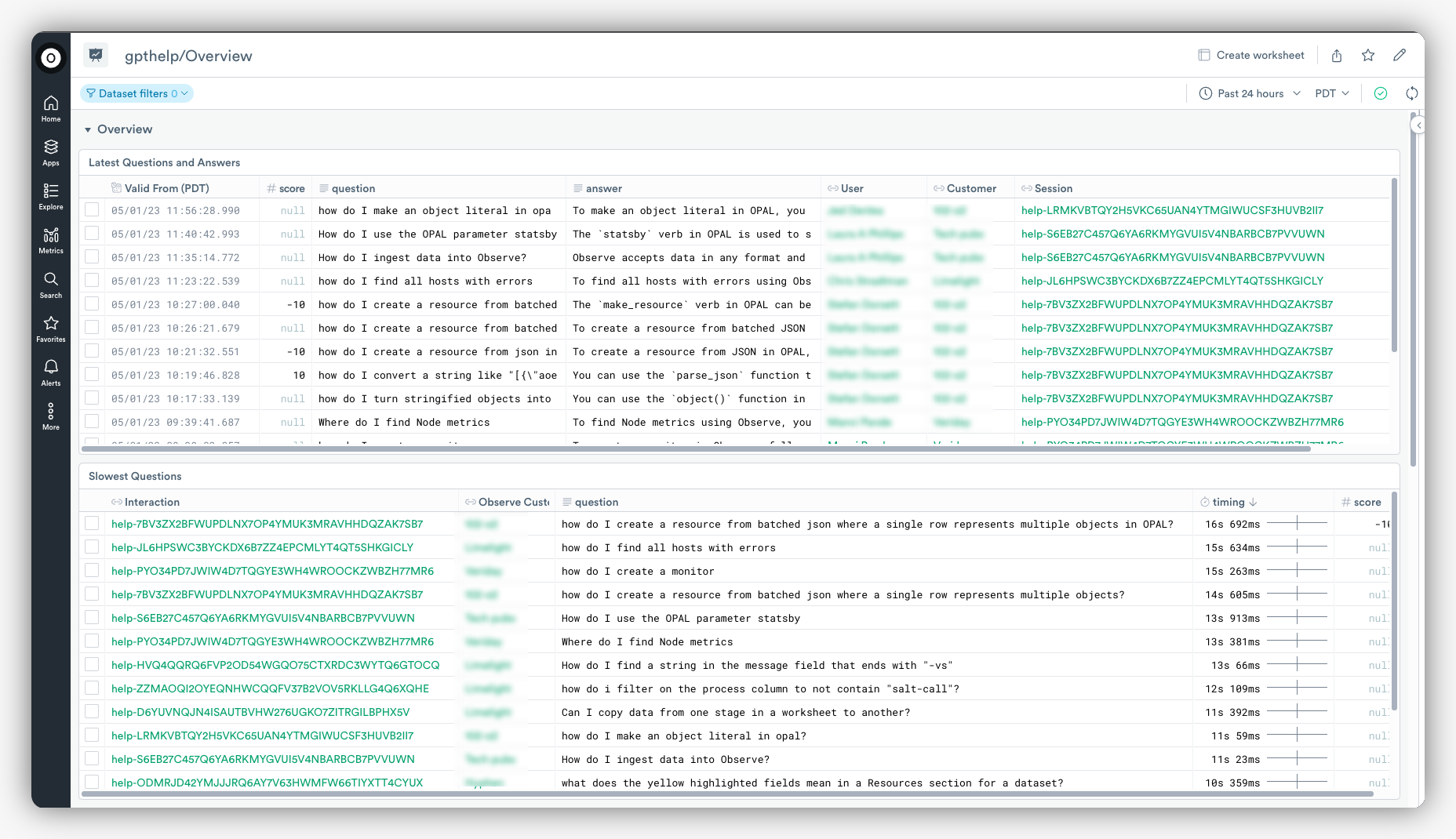
Next, we integrated this technology into our build system and web services and introduced it internally. This allowed us to uncover numerous real-world use cases, as our own engineers use it to answer questions. We now capture data from these systems with details about questions, answers, and user ratings, to Observe itself, providing a convenient dashboard that displays the “helpful” and “not helpful” ratings for each interaction, as well as performance and usage metrics. This insight enables us to understand the system’s behavior, which in turn guides the subsequent stage of product development.
An aside: Sending structured data to Observe in Python is very simple; we just print a JSON object to the standard out and pick it up from the container logs. parse_json does the rest when building our datasets.
# python
# make API request
startTime = datetime.datetime.now()
answer = openai.ChatCompletion.create(
model = HELP_MODEL_NAME, temperature = temperature,
messages = messages)
# log time and structured data
endTime = datetime.datetime.now()
print(endTime, json.dumps({
“event”:”question answered”,
“question”:question,
“previous”:previousQuestions,
“answer”:answer[“choices”][0][“message”][“content”],
“session”:sessionId,
“duration”:(endTime-startTime).total_seconds()}), flush=True)
// OPAL
// parse the data into a JSON object – cut out the date
make_col obj:parse_json(substr(log, 26))
// project to top-level columns for convenience
make_col event:string(obj.event),
session:string(obj.session),
question:string(obj.question),
answer:string(obj.answer),
previousQs:array(obj.previous),
duration:duration(obj.duration)
Thoughts, and What’s Next
One fascinating aspect of teaching GPT models about Observe is the phenomenon of “hallucinations.” In language model terms, a hallucination occurs when the model predicts something that sounds plausible but doesn’t exist in reality. Though they can be quite bothersome when accuracy is crucial (and why you shouldn’t use ChatGPT as a reference library!), some hallucinations reveal hidden truths. In fact, a few of them exposed feature gaps in our system by attempting to use features that should’ve existed but didn’t, for whatever reason.
Filling some of these gaps turned out to be relatively simple, and we ended up modifying the system to align with the model’s suggestions. Now, for instance, you can add flags after the trailing slash in a regular expression, without resorting to match_regex() and its third argument. So, perhaps it’s time to welcome our new robot product manager overlords with open arms!
filter match_regex(log, /error/, ‘i’) // old annoying way
filter log ~ /error/i // new cool way
There’s a Co-Pilot part of this assistant suite, where we use the GPT-4 model to generate OPAL code in worksheets. I often find these suggestions quite helpful, and getting that to work well has its particular challenges, that I hope to talk about in a future blog post. With this feature now accessible to everyone, we’re eager to witness more “helpful” than “not helpful” buttons being clicked. We’ll continuously improve its strengths, tackle shortcomings, and ensure that Observe helps you conquer even the most daunting observability obstacles.

Sure, the tech is still in its early days, and we face hurdles like context size limitations and occasional slow API responses. Yet, it’s clear that this feature can truly enhance the way you interact with the platform. We’re genuinely excited, as it appears we’re at the very beginning of a new way of helping engineers and other observability users around the world!
If you’d like to try out our latest GPT-Powered integrations then click here to request trial access now!