
What We Learned Building O11y GPT: Part I
 By Observe Team May 9, 2023
By Observe Team May 9, 2023
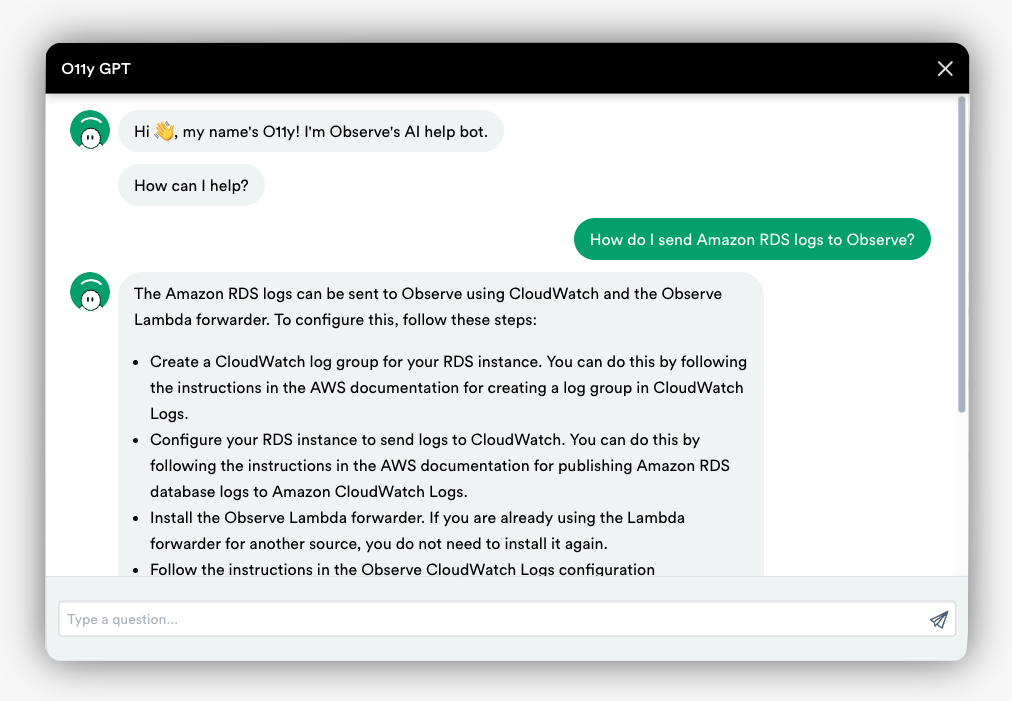
Upon the release of GPT-3.5, we began inputting our documentation and posing questions, from “What does Observe do?” to “How do I summarize daily errors from last week?”
Introduction
Observe uses the large language models from OpenAI to power technology that assists users in learning and using the system. This blog post talks about how we use the current capabilities of these models for our O11y GPT Help bot, and what we’ve found works best to get good results. The audience is anyone interested in the capabilities and limitations of current LLMs, as well as engineers looking to use these models for themselves.
Model Constraints in GPT-3.5
GPT-3.5 (“ChatGPT”) excels at processing text and extracting key points, making it well-suited for providing succinct help and instructions. Upon the release of GPT-3.5, we began inputting our documentation and posing questions, from “What does Observe do?” to “How do I summarize daily errors from last week?” and got mixed results. These models have a restricted attention span — the total tokens for context, instructions, questions, and answers must not exceed 4097 (for ChatGPT; GPT-4 allows somewhat more). A “token” corresponds to roughly one short word or one-half of a long word. Consequently, the amount of instructions, context, and user questions we can provide in a question while leaving room for the answers is limited.
That’s a challenge as our documentation is around 200,000 words long and keeps growing — three novels worth! It’s impossible to fit all of it within the 4097 tokens available for instructions, context, questions, and answers. So, we need to find a way to choose the most relevant context from all the available information and then simplify it for the user. To do this, we apply a concept from machine learning called embeddings.

Embeddings to the Rescue!
“An embedding is a point in feature space!” says the linear algebra expert. If you’re familiar with maps, think of it as a GPS coordinate in three dimensions: north or south, east or west, and up or down. Imagine a library with books on shelves, and each book has its own GPS coordinate. If the books are sorted by subject and you know the subject of a question, you can find the right books by going to the coordinates of the subject. For example, to find a Miss Marple book, look in the Murder Mystery section. We organize our library using precise GPS locations.
However, this analogy has its limits. GPS coordinates have three dimensions with clear meanings, while embeddings have more dimensions with meanings that are harder to understand. These meanings are not set by people but are found through complex methods like clustering and model training. Any idea you can think of can be turned into an embedding value, and similar ideas will have close values.
At Observe, we apply the Ada-002 model to compute embeddings, resulting in a 1536-dimensional vector. We then normalize these vectors to a unit length and insert them into a spatial index. Although we use a library called FAISS, we could perform a brute-force search since our word count only reaches a few hundred thousand. Computers can quickly handle this task if needed! As the open-source tools are there, we might as well use them, and save some cycles. By comparison, some current start-ups create online databases that perform similar embedding indexing functions that can run on a much larger scale, but that dependency isn’t needed for this use case.
Before we compute embeddings, we simplify our documentation by dividing it into smaller parts, each with 500 words or less. We then find the most relevant sections to answer specific questions. During the pre-processing process, we examine our documentation, separate each sub-section into a mini-document, and generate an embedding for each one. To improve speed, we batch 500 documents per request to the OpenAI API — a highly recommended technique! These embeddings are then stored in a FAISS index. When a question arrives from the user, we compute its embedding, identify the closest document segments in the embedding space, and use them as context when generating the answer.
Unique Challenges Remain
OpenAI offers a model pre-trained on a vast range of human knowledge. It understands topics like computer networks, log files, and network packets, as well as Grandiflora roses, astronomy, and tasty blueberry crumble pie recipes. However, some subjects are more relevant than others, and interpreting human text can be tricky due to its ambiguity. The model also lacks updates from the past year or two and specific details about Observe’s inner workings. Therefore, we rely on the model’s general understanding of the world to make sense of specialized Observe information when we provide it as part of a question to be answered.
The system isn’t perfect yet. For instance, the model learns from a lot of Python and JavaScript. Both languages use strong, but sometimes slow, advanced regular expression syntax. They have features like trailing context and non-greedy matches, which the faster POSIX regular expression syntax used by Observe doesn’t support. Even when we give clear rules on what’s allowed and what’s not, the model might make mistakes and use its Python knowledge.
In the next part, we’ll take a look at how we augment the basic model to make it more fit for this particular purpose!