
Understanding High Cardinality in Observability
 By Amit SharmaMay 15, 2024
By Amit SharmaMay 15, 2024
Cloud-native environments have revolutionized how applications are built and deployed, offering unprecedented scalability, flexibility, and resilience. However, they also bring unique challenges, including managing high cardinality metrics due to an exponential growth of data volumes in cloud-native environments.
This blog will explain high cardinality in the context of Observability, the causes of high cardinality metrics, the challenges they present, and strategies for managing them effectively.
What is High Cardinality?
Cardinality refers to the number of unique combinations a particular metric can take. What would make cardinality increase? Dimensions. They are the key-value pairs that can uniquely describe a metric. For example:
{2024-05-14_17:32:00} {metric: resp.code} {dimensions [user.segment:premium]
[userID:1234][action:make_payment][version:1.21]} {value:520}
Dimensions refer to the keys associated with metric data within the system, such as userID or service version, as shown above. Dimensions arise because of additional tags, attributes, labels, or properties that we assign to a metric so that, later on, we can analyze or interrogate the data in a more granular fashion. Adding dimensions increases the total number of possible combinations, also known as cardinality.
What Are The Causes of High Cardinality?
To understand how cloud-native environments can escalate cardinality, check out the simple illustration comparing traditional monolithic apps vs. distributed microservices-based deployment in Kubernetes and see how cardinality explodes from 20 thousand unique metrics to 800 million!

The following characteristics of cloud-native apps lead to this explosion in cardinality:
- Microservices Architecture: Cloud-native applications often use microservices, where each service generates its own metrics. As the number of services grows, so does the number of unique metric dimensions.
- Dynamic Environments: In cloud-native environments, instances of services are created and destroyed dynamically based on demand. Each instance will generate unique metrics, adding to the cardinality.
- Rich Instrumentation: Detailed instrumentation is essential for monitoring and troubleshooting. However, this can lead to many unique metric labels, contributing to high cardinality. OpenTelemetry instrumentation creates tags that make correlations easier but add to cardinality.
- User-Specific Metrics: Metrics that include user-specific information, such as user IDs, session IDs, or request IDs can allow you to pinpoint whether a specific high-value customer is experiencing latency issues– essential information to deliver flawless end-user experience; however, capturing these dimensions will create extremely high cardinality due to the vast number of unique users and sessions.
- Environment-Specific Metrics: Metrics that vary across different environments (e.g., development, staging, production) or cloud regions/availability zones can also increase cardinality. Teams may also run multiple versions of the service for testing and experimentation.
Challenges of High Cardinality Metrics
High cardinality is challenging to manage because it increases the number of time series and the complexity of queries. As the number of time series grows, queries become more computationally expensive. Additionally, any significant event, e.g., a code release involving immutable infrastructure, will result in a flood of simultaneous writes to the database.
- Performance Degradation: The more unique metrics there are, the more computational resources are needed to process and query them. This can lead to performance degradation in monitoring systems.
- Complexity in Analysis: High cardinality can make analyzing and interpreting metrics difficult. Finding meaningful patterns or anomalies in a vast sea of unique metrics can be challenging.
- Cost Implications: The increased storage and processing requirements directly translate to higher costs.
Many observability vendors cannot handle the scalability challenge created by high cardinality, and certainly, they cannot do so cost-efficiently. Their documentation warns users against sending dimensions with a high number of potential values or recommends keeping dimension values below a hard limit to avoid performance and/or cost penalties:
- Prometheus recommends to keep cardinality under 10 and cautions against overusing labels

- APM vendors like New Relic caution about the performance impact of high cardinality metrics
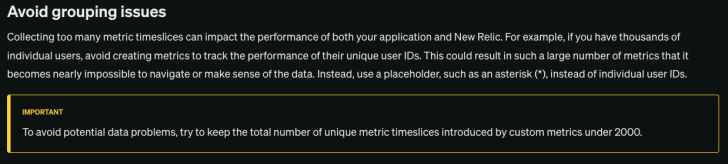
- Metrics-based solutions also limit the unique labels per metric.

To meet vendor’s limits and contain costs, companies are compelled to use sub-optimal workarounds:
- Metric Aggregation: Aggregating metrics at a higher level can reduce cardinality. For example, instead of tracking metrics for each user, you can aggregate metrics at the service or endpoint level.
- Filtering and Sampling: Filtering means dropping less important labels, and sampling involves collecting metrics from a subset of events or requests rather than all of them.
- Metric Retention Policies: Define retention policies to manage the lifecycle of metrics. For instance, keep detailed metrics for a shorter period and aggregated metrics for longer periods.
Granularity vs. Performance and Cost Tradeoff
Workarounds and vendor limits imply that teams either lose granularity and details when they analyze data or face massive cost overruns. Do your dashboards come to a grinding halt or are you spending thousands of dollars on custom metrics with traditional observability solutions? You can ingest all data without losing granularity at a fraction of the cost with Observe.
Infinite Cardinality with Logs
Metrics-only solutions fall short in supporting high dimensionality and cardinality. So, how do you capture dimensions such as user IDs that provide granular details about customers’ experiences with your applications?
Logs can support infinite cardinality due to their flexibility in handling structured, semi-structured, and unstructured data. However, much of that support is lost when they’re indexed into time series databases. These tools are optimized for storing and querying structured data with predefined schema, effectively forcing index-time schematization of the dimensions that cause cardinality explosions.
Challenges with Traditional Log Management Solutions
Many observability vendors cannot handle the high volume of fast-moving log data from cloud-native distributed systems such as Kubernetes. Solutions such as Datadog use an index-based approach and recommend indexing only a subset of the ingested data, creating visibility gaps.
Furthermore, retaining log data for extended periods in Datadog can become prohibitively expensive, so Datadog recommends extracting metrics from logs for historical analysis.
Why Does Datadog Make You Pay Twice to Analyze the Same Data?
Datadog utilizes separate backends for its log and metrics solutions. So, when it derives metrics from logs, a separate environment in the time series database must be provisioned to generate insights. This additional cost is then passed on to Datadog’s customers as custom metrics.

Even if you are running a moderately sized cluster comprising 200 nodes and want insights on userAgent, sourceIPs, nodes, and status codes, similar to the examples shown above, you could potentially be looking at 1.8 million custom metrics and an additional cost of $68,000 per month.
Modernize Your Log Management with Observe
Observe is a modern, cloud-native observability platform that delivers fast performance on a petabyte scale while minimizing the total cost of ownership.
In Observe, logs are captured and stored without losing their inherently wide variety of data types and formats. We can then use them to answer questions without prior knowledge of their structure. This allows Observe customers to handle unlimited unique values across multiple dimensions, including dynamic and unpredictable data points such as user IDs, session IDs, and error messages.
In the Observability Cloud, logs can accommodate the vast and ever-changing nature of modern applications, providing detailed insights and enabling comprehensive analysis without being constrained by the limitations of traditional cardinality management. This flexibility makes logs essential for monitoring, troubleshooting, and gaining deep visibility into complex systems.
The primary reason why teams use custom metrics instead of logs is traditional log management vendors offer only 7, 30, or 90 days of retention in a hot state. Beyond the default retention, data needs to be tiered and stored in a warm, cold, or frozen state, rendering it useless for timely analysis and visualization.
Observe offers the industry-leading retention period of 60 days by default for logs and 13 months for metrics. Data is always kept in a hot state, so your dashboards refresh or alerts fire within seconds.
Ready to solve performance issues or cost overruns caused by the high cardinality data? Start your Observe journey with a free trial.