
Observability Scale: Scaling Ingest to One Petabyte Per Day
 By Observe Team January 23, 2024
By Observe Team January 23, 2024
Here’s a guest post from our very own Matthew Fleming!
At Observe, we want to provide observability into your data — all your data. Some customers and prospective customers are running deployments with thousands of nodes and hundreds of apps, all emitting telemetry that is useful both for debugging and for general insights into the health of their system. We provide an observability platform that allows for monitoring and introspection, without the customer needing to ingest only samples of the data. This means handling very, very large amounts of data. Our current largest customer has sent us over 200 TB per day for several weeks, and we want to be able to support even larger customers. So we set ourselves a target of being able to handle a petabyte (1 PB, or 1024 TB) of ingested data per day for a single tenant.
Why for a single tenant? Scaling ingest across a whole cluster, with many tenants, wasn’t as hard a challenge. Even before onboarding the customer who sent us 200 TB/day, our aggregate ingest in production was already around that volume. Furthermore, many customers have a diurnal cycle, sending sometimes twice as much data during the day as during the night. So we often speak of the aggregate ingest over a full day. 100 TB/day would be about 1.2 GB/s steady state. But the reality is that we’d more likely see closer to 1.6 GB/s during the daily peak and 0.8 GB/s in the middle of the night.
The journey to ingesting 1 PB/day for a single tenant came in several steps. Two years ago we could perhaps handle 30 TB/day for a single tenant. A year ago we onboarded a customer who eventually was sending us 200 TB/day. And now we’re ready to handle 1 PB/day for a single tenant.
Observe Ingest Architecture
To explain how we accomplished this and the changes we’ve made, let’s first go over the basic layout of the ingest pipeline. The job of ingest is simple:
- take a customer request submitted via HTTP (JSON, Prometheus, OpenTelemetry, etc.)
- validate the data (otherwise return an HTTP 4xx error)
- ensure the data will eventually end up in Snowflake in the customer’s database
- reply with HTTP OK (200)
Of course, it’s never this simple. HTTP responses should come in a matter of milliseconds. Loading data into Snowflake takes on the order of seconds even for just a few bytes, so at least some batching is required. Customers want their data visible as soon as possible, but the more we batch at each layer, the less the cost per byte. This means that ingest has to balance costs (compute, storage, Snowflake credits) versus end-to-end latency, while maintaining a high overall throughput.
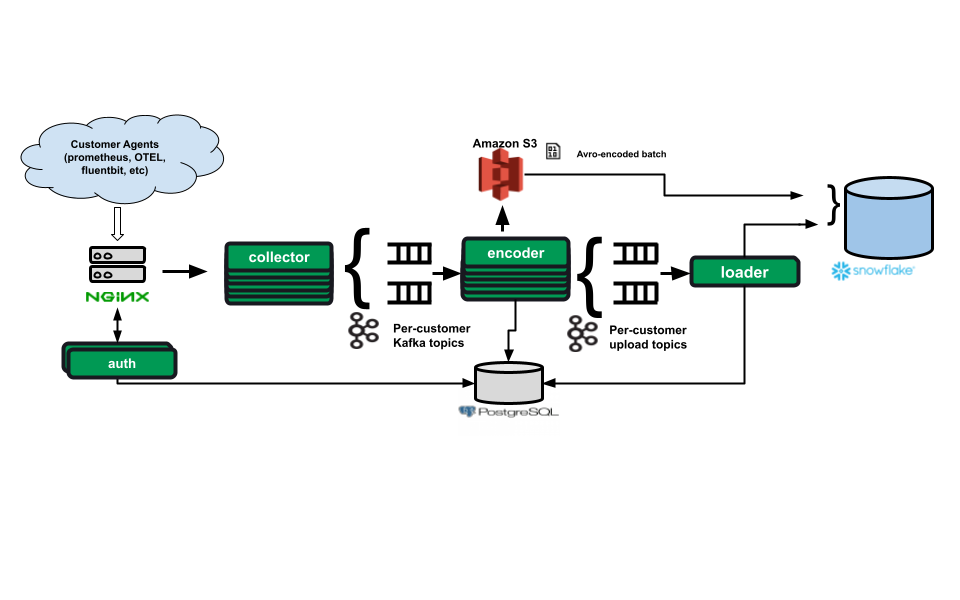
Simplified diagram of the Observe ingest pipeline
Data from the customer gets into Snowflake by flowing through several agents. The important parts for scaling the normal ingest flow are:
nginxhandles load balancing off the shelf. It also handles authentication using anauth-url. Requests are then routed to acollector.- The
collectorreceives an HTTP payload, decodes it, and converts the data to a schema-independent format. This input-independent data is persisted inkafkabefore replying to the customer’s request. kafkareceives data from thecollector, using one topic per customer (more on that later). Kafka is a good fit as it’s a fast streaming system that ensures durable writes of data, so we can quickly acknowledge requests. Once the data is persisted somewhere, we can finish transforming it into a form suitable for Snowflake at our leisure. This allows us to tolerate restarts without losing any customer data.- The
encoderreads fromkafka, one worker per topic/partition. The encoder groups the data read fromkafkainto S3 files with a schema suitable for adding to the per-customer Snowflake database. - The
loadertakes groups of files in S3 and passes the names to aCOPY INTOstatement in a stored procedure. This stored procedure also manages watermarks (a record of the highest kafka offset seen for each topic/partition), ensuring that we ingest each piece of data only once. Snowflake limits us to 1000 files perCOPY INTOstatement.
This setup gives us several mechanisms for scaling. Both the collector and encoder are kubernetes deployments, so we can add more pods to either one to keep the load per pod reasonable. And we can increase the number of partitions in kafka for the per-customer topic to ensure each encoder’s partition worker has a reasonable load.
Scaling the Loader?
In order to understand what the loader really does, we need a little history and some more details. In the early days of Observe, all data from the customer initially went into a single table. Other datasets were derived by transforming the data from this single table — pulling out metrics, or logs, or data specific to e.g. one customer app.
This made transforming the data more expensive, as all the data had to be queried in order to e.g. make a graph of a metric; we couldn’t just scan the metric data. So we developed a concept of a datastream — each datastream is a logical unit of data flowing into the system. These are usually created by apps installed by the customer, for instance a Kubernetes app that tracks the customer’s kubernetes state, deployments, k8s logs, etc., or an AWS app that tracks their EC2 instances, etc.
While the customer’s data is still all in one large data lake, we actually write the data to multiple Snowflake tables, one per datastream. From the loader’s perspective, each table can only be written to single-threaded because of various table locks involved in the transaction. The initial implementation of this split among datastreams kept the loader the same and just changed the stored procedure to multiplex where the data was sent, using Snowflake SQL to INSERT ... WHEN to the appropriate table.
Performance measurements showed we could ingest more than 2GB/s (enough to handle load spikes) if we used a large enough warehouse. So the numbers worked out to ingest 100TB/day through the loader, without additional changes. We were ready for a customer!
Ingesting 100 TB of Observability data per day
For our first customer wanting 100 TB/day, we took their expected ingest rate (100 TB/day), computed how many collector and encoder pods we needed for this bandwidth, and scaled the cluster to a size we thought would handle the traffic with enough overhead left over for load spikes.
Unsurprisingly, things didn’t work the first time. Our collector pods all started crashing because they were running out of memory (i.e. an Out Of Memory error, or OOM). Each protocol we accept has different overheads in CPU and memory, and this customer’s data was notably different from the aggregate workload we were already handling in another production cluster.
We were able to grab some memory profiles before a pod OOM’d and quickly fixed the first issue, which was specific to the Golang programming language. Our intermediate data format is serialized using protobufs, and because protobuf is specific about strings being valid UTF-8, the internal format treats strings of customer data as a protobuf bytes field instead. So in the Golang implementation of the collector, we convert a string that came from parsing the customer data into a []byte. Unfortunately, this results in a copy of the data. Since a []byte is mutable and a string is not, the below code actually copies the contents:
asBytes := []byte(stringVal)
But, if one knows for certain that the []byte slice is never written to, there’s a hack for converting without a copy. This gets easier in more recent versions of Golang, with the unsafe package:
func UnsafeStringToBytes(s string) []byte { if len(s) == 0 { return []byte{} } return unsafe.Slice( (*byte) (unsafe.Pointer((*reflect.StringHeader)(unsafe.Pointer(&s)).Data)), len(s)) }
There are other ways to do this, but the above worked. Since it was a simple change, we hot-fixed the cluster, and had the customer turn the spigot back on. The flood of OOMs stopped!
An Aside on Programming Language
The initial implementation of the collector and encoder was in golang, because it’s a great language for rapid prototyping, and if we couldn’t implement ingest at all we wouldn’t be able to implement the rest of the system. However, as a garbage-collected language, it’s inefficient for workloads that involve very short-lived memory allocations. This is exactly the pattern that ingest has: data comes into the system in chunks, we process it, and hand it off to the next stage of the ingest pipeline. Each submission is processed in a few milliseconds. Converting the collector and encoder from go to C++ was an instant win in terms of the CPU and memory needed to handle the ingest volume; the first pass at the replacement code used about half the CPU and half the memory, just from eliminating the garbage collection. But at the time we on-boarded this customer, only the encoder was in C++; all but one of the collector endpoints was still being handled by the Golang version of the collector.
Ramping the Ingest Volume Further
As the customer ramped up their data, we experienced more issues. A new source of their data was in CSV format. Converting this to the internal representation effectively made each row of the CSV into an object (key → value representation). This meant we stored a copy of each key for each row, which quickly ran us out of memory again. This time the solution was to add a custom internal format for parsed CSV-type layouts, allowing us to only encode the keys once for the whole table, instead of each row.
At this point we were handling about 200 TB/day of data successfully. But the Snowflake costs were higher than we wanted. The problem was that the loader was still inserting to all the different datastream tables in a single transaction. The added overhead of these extra table writes meant we had to use a larger warehouse to keep latencies reasonable, and the cost of the larger warehouse made the overall ingest cost more than we considered reasonable.
To fix this, we spent several months breaking up the loader’s pipeline to aggregate by datastream, then run inserts to different datastreams in parallel. This is complicated by the fact that we want to run as few insert transactions as possible, only breaking up into parallel inserts if we have large amounts of data going to several datastreams. It ends up being a version of the knapsack problem; fortunately we only needed an approximately-good solution.
Running parallel datastream inserts was a win/win: the latency dropped, and the costs dropped as well.
The parallel datastream insert was the last feature needed to declare success for this customer. They were happy with the latency, and we were happy with the ingest costs.
Observability at Scale: Reaching 1 PB per day
After our experience with the customer sending us 100-200 TB/day, we felt very close to the next goal of 1 PB/day (a steady state of 12 GB/s, so we’d need to be able to handle expected daily highs of 15 GB/s, and also not fall over if we got a peak of 30 GB/s). Each datastream can definitely ingest 1 GB/s sustained at reasonable costs, even with multiple inserts running on the same Snowflake warehouse, using the parallel datastream inserting code we developed. So as long as a customer didn’t need to send more than 1 GB/s per datastream steady-state, the loader was ready to handle 1 PB/day (spread across 15 datastreams). And we already knew the collector, encoder, and kafka scaled up essentially linearly.
The encoder can process 25 MB/s from a single kafka partition without using more than a reasonable amount of CPU. In order to do 1 PB/day, we would need about 400 partitions for the per-customer topic. But there’s one more wrinkle here. In order to minimize the amount of time it takes for data to reach Snowflake, each encoder thread handling a kafka partition emits an S3 file every 10 seconds. With 400 partitions, that’s 400 threads emitting a total of 2400 files per minute. But we can only COPY INTO 1000 files at a time, and with 1 PB/day volume, the loader inserts take closer to 40 seconds than the sub-10 second we can get with smaller volume. So the math doesn’t work out — at 1 PB/day we’re creating more files than the loader can handle.
The solution is something we had wanted to do when developing the per-datastream loader inserts, but couldn’t at the time due to kafka limits. Kafka running on zookeeper has a limit of about 10k partitions per broker. So we can’t use a kafka topic per datastream for all customers without hitting this limit. Upgrading kafka to a version that doesn’t use zookeeper is on our backlog, but we want to support a 1PB/day tenant now.
The solution is to use a topic per datastream only for the highest volume customers. And with that code now written and merged, we are now able to handle at least 1 PB/day for a single tenant.
Conclusion
Scaling a system is a journey of finding and breaking down bottlenecks. Some of them can be found ahead of time, but inevitably there will be something unexpected. With the work described, we ramped ingest from 30 TB/day to 200 TB/day, improving the efficiency of the CPU/memory bound agents and improving the scaling of our use of Snowflake. We’re now ready for 1 PB/day from a single tenant.
Future Scaling and Cost Improvements
There’s plenty more to be done to make ingest more efficient and more scalable. The loader bottleneck per table can be removed by leveraging Snowpipe Streaming, which will also lower ingest latencies overall and reduce costs. A different internal format for communicating the customer data from the collector to the encoder can reduce both the memory and CPU needed to process the data. And C++ gives us very fine-grained control over memory allocation and data formats, which will likely improve throughput per core even more.