
Lost Logs: Log Retention vs Observability Cost
 By Jack CoatesApril 9, 2024
By Jack CoatesApril 9, 2024
Logs give such powerful visibility into what an application system is doing, and auditors want to see them. The problem is, keeping long term logs online in legacy platforms can cost an arm and a leg. Let’s look at ways to solve that problem!
The Cost Bomb is Ticking
There is a huge cost escalation challenge faced by companies using legacy observability tools. Organizations all over the world are facing a turbulent environment as their legacy tools struggle with moving to the cloud, falter, and get acquired. Splunk, AppD, NewRelic, SumoLogic, Lightstep, who’s next? Customers of these companies can see significant annual increases in total cost of ownership (TCO), sometimes over 30%, while their budgets and headcounts are being slashed. Escalating data volumes due to CI/CD delivered microservices, more types of data, regulatory requirements for greater and greater data retention, and hard requirements to search everything faster so that fewer employees can do more work: it’s no wonder that everyone reports financial strain. Observe’s cloud native architecture can help, delivering observability into operational, compliance, and security problems on the industry’s first true data lake.
Identifying the Problem
The typical symptoms of the cost bomb dilemma are expanding data volumes, strain on resources, and financial burden. Organizations are faced with decisions to omit or sample data to stay in their financial expectations… or worse yet, route data to inaccessible storage so they can technically meet compliance requirements. Log filtering, retention period reductions, and occasional rehydration of data from cold storage are the tools of choice when you have to stay on a legacy data solution. Organizations have been struggling putting data into cold storage, omitting their metrics, deciding to only use metrics rather than logs. Worst of all, the technologies that organizations are embracing to handle modern scale and architecture are exacerbating the dilemma. For instance, cloud native Kubernetes infrastructure intensifies the data explosion challenging organizations, even when it’s used as a service from an infrastructure provider. Ephemerally scaling microservices produce amazing amounts of logs, metrics, and traces which are critical for understanding high-speed environments. Organizations embracing these technologies struggle to mitigate the technical challenges and business impacts of cost explosions in their legacy Observability tooling.
Legacy architecture binds storage and compute costs together because it was designed for the on-prem world, fleets of servers with monolithic services that needed manual scaling and planning. That old school architecture hurts even more for security use cases, where heavy data processing to normalize data drives costs through the roof without adding appreciable value.
The Observability Cloud Answer
Observe provides these organizations with an alternative: the Observability Cloud is a proactive solution to mitigate cost explosions and their business impact. Where legacy vendors are quietly dropping log retention levels or recouping storage costs with extra product licenses, Observe is upfront with robust storage, efficient data handling, and scalability. Where your old on-prem system held data as long as you wanted, you might be surprised to find the new cloud variant drops your logs into the bitbucket after a few weeks. That’s a really ugly problem for anyone working with the US Federal system, trying to answer Know Your Customer (KYC) questions, or forensically investigating how a breach occurred. Compliance just keeps getting harder to hit, PCI, StateRAMP, ISO 27002, &c retention requirements coming. Using Observe alleviates the need for log filtering, retention adjustments, and data rehydration by offering streamlined data management and full control over separated storage and compute.
Tackling Data Explosion in Retained Logs
Our Observability Cloud is specifically designed to handle massive velocity, variability, and volume. The data explosion from cloud native microservice orchestration frameworks like Kubernetes has driven that design. It takes a modern architecture to keep your retained data live and fresh for as long as you need. Having all this data is not sufficient, as Cindy Sridharan writes, “Logs, metrics, and traces are useful tools that help with testing, understanding, and debugging systems. However, it’s important to note that plainly having logs, metrics, and traces does not result in observable systems.” It is a fundamental starting point; you certainly won’t have observable systems if you’re not able to keep the data to observe them with.
What if We Just Didn’t Log?
It’s worth noting that there are people calling for rethinking logging or even dropping the idea of logs entirely. Maybe we can rewrite our logs in structured formats, or maybe we can use traces as the primary tool for observability, or maybe the next app will be better designed. This is all for the good, traces are great and Observe has great tools for them. However, replacing all the existing stuff in order to improve its observability is a pretty tall order. What if the budget doesn’t allow for that? Should all the old monitoring systems be left in place alongside those legacy systems, so DevOps and SecOps teams have to swivel-chair from console to console to console? The budget definitely doesn’t allow for that.
Everyone needs the freedom to use technology approaches that work across whatever type of data is coming from all of their systems. Logs are a baseline of Observability because they’re always available. Metrics allow useful questions to be answered for lower cost. Traces provide deep awareness of system state. All three have great value on their own and in combination, and only Observe brings them together in a single console as a single product.
Using Logs Well in Observability
Observability from log data can be a powerful tool, if your platform can economically handle the load. Observe’s intuitive Log Explorer helps analysts discover patterns, extract meaning, and isolate root causes quickly across tremendous scales of data. Materialize the data that you need when you need it, defer costs when you don’t. Most of all, consider what you could do with months of retained data instead of a week or two. If you’ve gotten used to those limits, it can hinder your ability to see the benefits of 13 month log data retention in Observe. Long term data is critical for:
- Security Incident Investigation: Detecting and investigating security breaches might require analyzing logs over a long period to understand the full scope of the attack, how it evolved, and what vulnerabilities were exploited. Long-term log retention enables better forensic analysis and understanding of the attacker’s methods.
- Regulatory Compliance and Auditing: Many industries require businesses to retain logs for extended periods due to regulatory compliance. Long-term retention ensures that you can fulfill legal and compliance requirements, even if incidents or issues are discovered weeks, months, or years after they occurred.
- Delayed Issue Discovery: Some issues might remain dormant for a long time before causing visible problems. By having access to long-term logs, you can trace back to when the issue initially started and identify its gradual progression, aiding in its resolution.
- Service Degradation Attribution: In distributed systems, service degradation or performance issues might be caused by interactions between different components. Long-term logs enable tracing these interactions over time to identify the specific components or interactions responsible for the problem.
- Data Correlation and Cross-System Analysis: When troubleshooting complex problems that involve multiple interconnected systems, cross-referencing logs from different systems over a longer period can help in identifying dependencies, correlations, and patterns that lead to the issue.
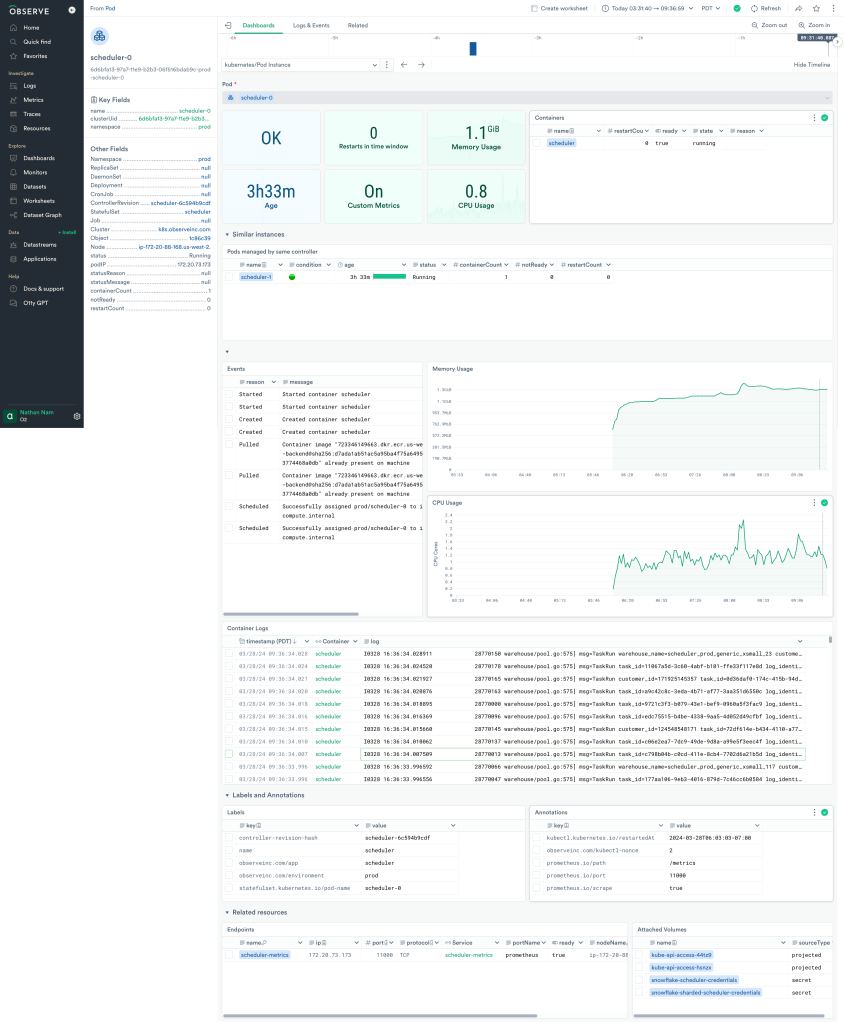
Cross-system analysis is particularly critical when you have access to many types of data from many components. For instance, here’s a production screenshot from our own Observe instance, O2, using logs, traces, and metrics to answer questions from our DevOps team every day.
The Security Observability Opportunity
SIEM’s failure to keep up with the cost-benefit requirements of modern organizations has opened the door to fresh approaches like Cybereason’s SDR (powered by Observe). Logs are a crucial driver of security and compliance use cases of course, and you can’t do Security Observability without them. Where SIEM falls down in the cloud is the forced requirement for massive, continual operational cost. Forcing data through a heavy transformation pipeline and running piles of outdated known-known searches “just in case” is yesterday’s approach. A modern approach allows you to select what you’ll normalize and how, and focuses on searching for what matters. Regulatory requirements are going up almost as quickly as Observability data generation, and keeping that data is critical to ensuring compliance. Applying bulk SIEM transformations across those high data volumes and keeping the duplicated data for prolonged data retention periods makes it really difficult to efficiently meet those data access and management requirements. Instead, a Security Observability approach collects and keeps the data that compliance needs, then applies limited transformation where and while it’s useful, eliminating the load of monitoring for no-longer-valid scenarios. “One size fits all” fits no one, and stretched SecOps teams don’t have the resources to sit at the end of a firehose of pointless alerts anymore.
Feed The Robots!
Whether it’s called Artificial Intelligence or cognitive computing or machine learning, any kind of automated analysis or assistance is only able to work on data it’s got access to. There’s no model of normalcy, there’s no anomaly detection, and there’s no conversational interaction with logs that weren’t saved. It’s too bad that so many Observability players suggest sampling data or routing it to cheaper locations instead of making it usable! A legacy cost model is a big driver for that sort of behavior. If you cannot afford to collect data, of course that’s a show stopper! But the more insidious problem with legacy systems is performance-driven data reduction. Any engineer’s first answer to a performance problem is the Jedi Mind Trick: ask “What is the problem you’re trying to solve?” and then find a way to either not do the thing, or do a lot less of the thing. That’s a fine approach, but we shouldn’t have to do it for questions of “can I even collect this data at all”. If you can’t afford to collect enough to do true observability in the first place, and then can’t keep the data long enough to build models from, your Observability product isn’t able to meet the promise of modern AI. Without sufficient data, you can’t rely on your Observability tool for:
- Anomaly Detection and Root Cause Analysis: In complex systems, anomalies might occur sporadically or over extended periods. Long-term log retention allows you to compare current events against historical data to identify unusual patterns that might not be noticeable within a short timeframe. This helps in performing effective root cause analysis and understanding the factors leading up to an issue.
- Trend Analysis and Performance Degradation: Some performance problems or resource utilization issues might develop gradually over time. With long-term log retention, you can track trends in system behavior and identify gradual degradation that might go unnoticed with shorter retention periods.
- Capacity Planning and Resource Allocation: Analyzing long-term log data can help in making informed decisions about capacity planning, scaling, and resource allocation. By studying historical patterns, you can predict future resource needs more accurately and avoid over- or under-provisioning.
- User Behavior Analysis: For applications with a user base, studying long-term log data can help in understanding user behavior patterns, preferences, and trends. This information can be used for improving user experience, tailoring content, and making strategic business decisions.
Finding The Value in Retained Logs
Logs remain a critical troubleshooting and security tool; you can technically do Observability without them but it’s a lot more difficult. Why go without the good stuff when you can have it all? Observe is designed to collect and store everything you need without breaking the bank. In Observe we use schema on-demand, automatic handling of indexes, automatic performance tuning, and more: these are features that support analysts diving right in. You shouldn’t have to start solving a problem by asking for a professional services design contract to revise your data pipeline. Most importantly, everything is in a single data store, behind a single flexible, time-aware language designed to support the breadth of Observability use cases. You’re not using SQL for the compliance store and KQL for the security store and PromQL for the operations store, in Observe OPAL can help for any data problem. This makes it easy to cross-train, easy to expand use, easy to keep your focus on improving your system instead of maintaining Observe. Try out the free trial today!