
GPT’s Implications for Security Observability
 By Jack CoatesJune 22, 2023
By Jack CoatesJune 22, 2023
It’s up to your organization to be vigilant and understand who’s inputting what data into the myriad services, apps, and features based on LLMs. If that level of observability sounds daunting, fear not, it’s why we developed the Observe App for OpenAI.
GPT and OpenAI are dominating headlines, and organizations of all sizes have scrambled to use and develop features that build on LLM technology. While there are immense productivity gains to be had from GPT, there are also security and data governance concerns. We’ve already seen notable instances of large enterprises putting a moratorium on the use of GPT due to fears about exposing sensitive data. This raises the question: How valid are those kinds of concerns, and what should an organization do to mitigate the ill effects that might occur with LLMs?
A Cause for Concern
So what is the cause of all the worry?
Organizations are concerned about users asking potentially risky questions. Because of the ubiquity of LLM features in software organizations need to be cognizant of the data sensitivity in questions posed to the GPT features being offered to their customers, as well as those sent to features in products of vendors they work with.
Is it enough to simply train users NOT to ask questions with sensitive data in it?
Probably not for most organizations, certainly not for large enterprises. It can be challenging to train users to recognize the sensitivity of data; someone who does not regularly work with customer PHI (Personal Health Information) or PII (Personally Identifiable Information) for instance might not think that an email address is sensitive. It’s not intuitive to everyone, but people can leave significant digital trails on the broader Internet, and triangulation from tiny segments of revealed data can be used to de-anonymize those people. Depending on the value of the target, even obfuscated fields may be worth an attacker’s effort to reverse. Obfuscating or encrypting sensitive data about real-world people and things is insufficient. Helping users to recognize what’s sensitive is certainly a valuable effort, but it’s not the complete story.
In addition to training, you should also consider visibility into potential failures of training. The logs of your GPT system are critical resources in this effort, showing the prompts that users offered and the results from the system, and metadata of the request. This type of logging is a rich corpus for data mining; not only for security risks but also for documentation and product updates. Clusters of similar questions can help you see what needs to be addressed.
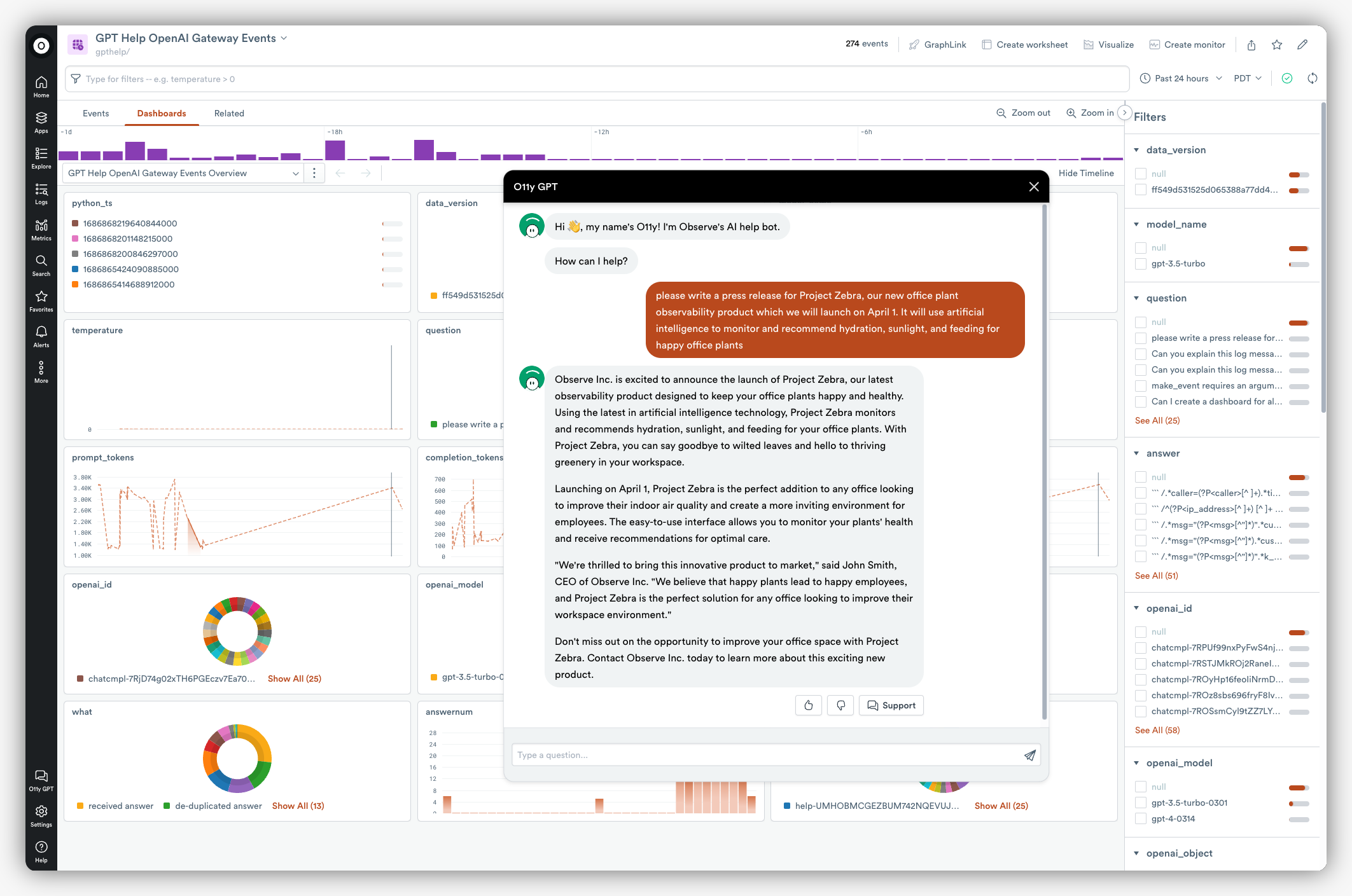
Personal information and compliance risks aren’t the only things to watch out for; another major source of concern is the exposure of internal information. Imagine someone asking, “Please write a press release for Project Zebra, our new office plant observability product which we will launch on April 1st. It will use artificial intelligence to monitor and recommend hydration, sunlight, and feeding for happy office plants.”
Because prompt inputs can be used to inform future models, this innocent question can turn into a surprising data leak or at least an uncontrolled flow of information. While that data is not as readily reversible as PII, the hints in a chat log can help attackers to determine context and target other penetration efforts. This is the concern that has led many significant manufacturers and software firms to declare internal moratoriums on large language model use. You can train users to avoid inputting sensitive information, but they won’t always be cognizant of what is considered sensitive.
Protective Contracts
If you use a third-party system for large language model writing assistance, then you’re inherently sending it data in the form of question prompts. That data can include sensitive information, such as project names or descriptions, people’s contact information, and much more. Since one of the suggested models for LLM use is to “rewrite this sample” or “format this data”, a user can easily be encouraged to post extremely sensitive material such as code snippets or tables of results. Even if the code is just a prototype, it can still expose intent, structure, function, and variable names, and access methodologies for planned integrations.
If your organization has done the needful with a vendor like OpenAI or Google to ensure that your prompts and answers are not used to retrain future models, then using potentially sensitive data should be safe to do. That is the approach taken by Observe’s helper bot (O11y GPT) and its code-completion feature, OPAL Co-Pilot. The remaining risk is in accidental mishandling of the data, which we will discuss how to detect later.
Your organization likely purchases software from a wide range of third-party vendors, and many of the vendors your organization works with have or will add features that use LLMs. It’ll be your responsibility to understand whether they are being transparent about the nature of these features and the contractual relationships they may or may not have with LLM providers. Making any assumptions about how data is being handled imparts risk.
Another alternative for addressing this issue is to avoid the third party altogether; organizations that run their own models and maintain their own data pools do not need to be as concerned with potential leakage via prompts used by or stolen from a third party. Running your own LLM comes with additional overhead, including operations and security complications, but each organization needs to weigh those considerations against its own needs.
Visibility into Queries
It’s up to your organization to be vigilant and understand who’s inputting what data into the myriad services, apps, and features based on LLMs. If that level of observability sounds daunting, fear not, it’s why we developed the Observe App for OpenAI. This App can give you visibility into OpenAI API calls so that you can know exactly what questions were sent to OpenAI and what answers were returned. If a user puts sensitive data into a question, you’ll be able to know.
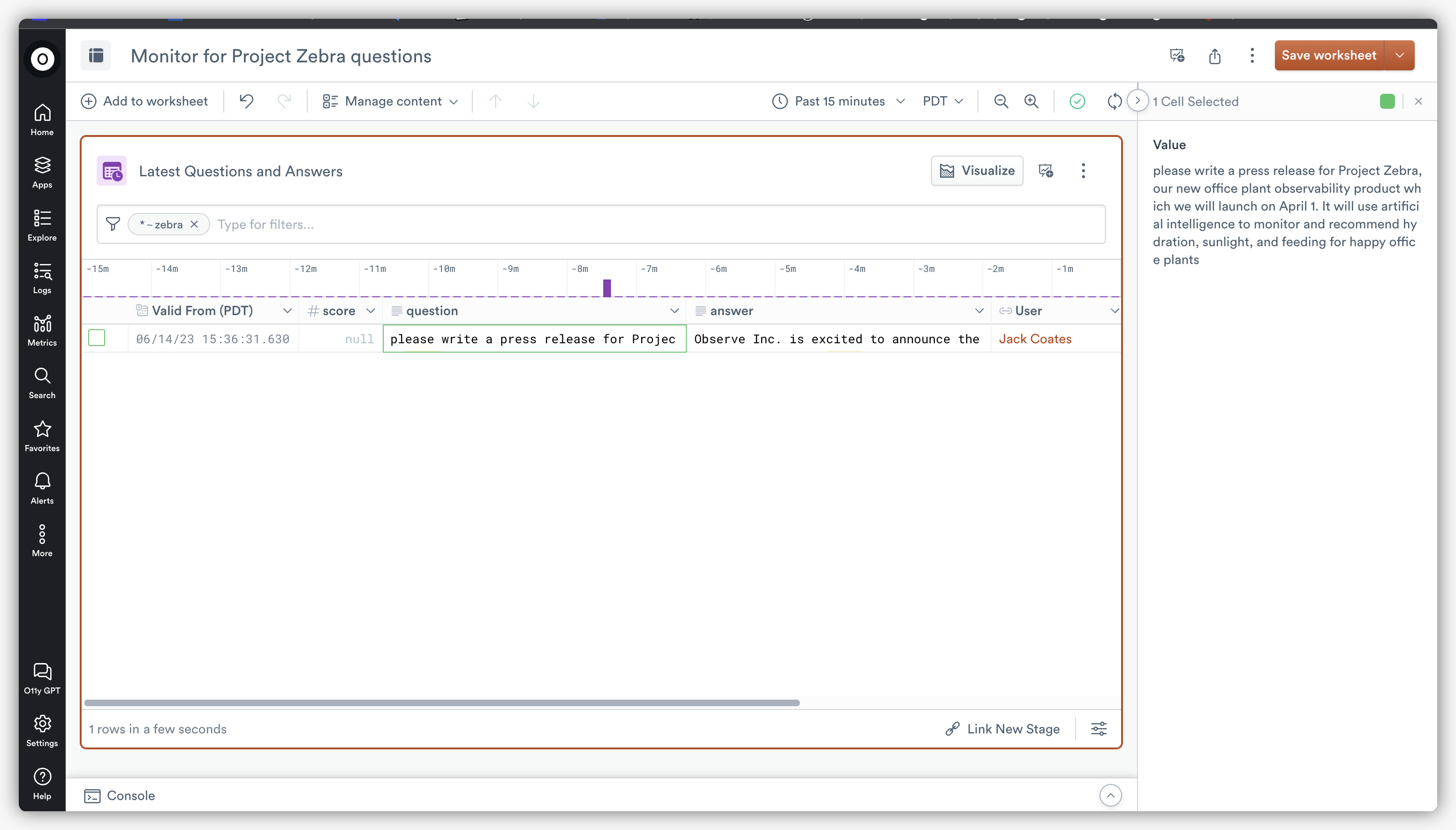
While this app is specifically designed for OpenAI, logging and monitoring the usage of assistants is just as valid for in-house LLM use. Any new tech introduction brings an obligation to review how your team can ensure it’s used safely.
Of course, every obligation for data collection is also a potential opportunity – the prompts from your user community can be a rich source of information. What are users confused about? What do they seek help with? You could even model questions to find commonalities and anomalies, assuming that a collection of prompts is allowed in your security model.
Planning Ahead
Your organization can enforce a moratorium for a little while, but history shows your colleagues will find a way around IT policy to use a tool they love. At the end of the day, the safest way to handle dangerous data is not to handle it, but you can’t trust all members of your organization to understand what’s potentially dangerous. It’s highly likely that the market will fragment and the technology will spread across ISVs (Independent Software Vendors) and in-house efforts; we’re already seeing AI features introduced in many of our daily productivity tools. All organizations need to use this time to establish a framework of policy by which you’ll monitor and approve, or lovingly correct, the observed end-user behaviors.
There is no regulatory framework on LLMs at this time, and there probably won’t be for the foreseeable future — efforts by incumbents to raise the drawbridge notwithstanding. Organizations need to take responsibility for their own regulatory stance and get visibility into what’s happening. Institute a plan to get visibility in place now before more LLMs, and features powered by them, make it even harder to monitor usage.