Modern Cloud-Native Architecture
Observe’s Modern Cloud-Native architecture delivers an unparalleled combination of fast-performance, effortless scalability, and dramatically lower cost. AI-Powered Observability enhances productivity, speeds up troubleshooting, and reduces time to resolve issues.
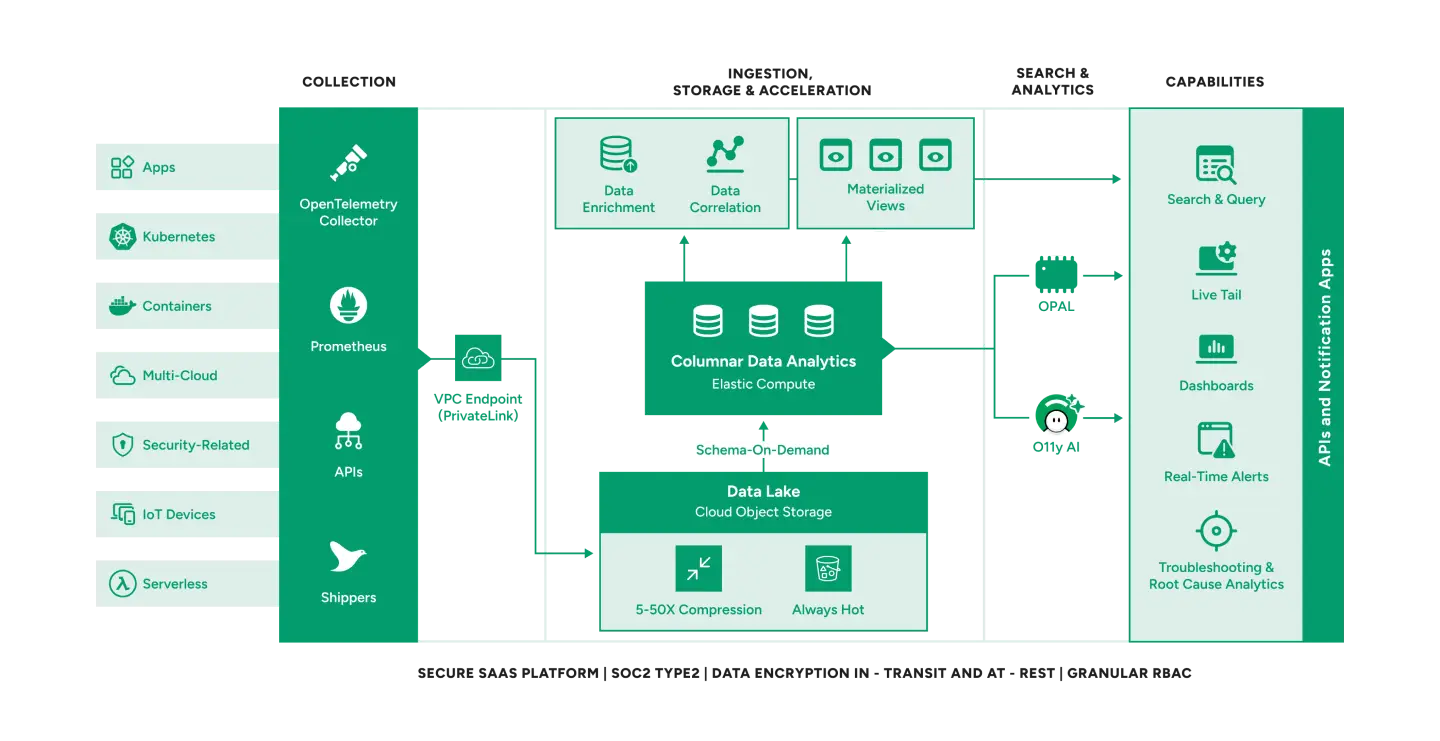

Open Data Collection
Customers get complete flexibility on bringing data from their entire stack into Observe using open, vendor-neutral OpenTelemetry Collector, Log Shippers, Prometheus, APIs, and more.
Unified, Open Data Lake
Metrics, Traces, Logs, Events, and relevant business data is stored and processed in a unified Data lake built on low cost object storage (AWS S3). Apache Iceberg – a distributed, community-driven, 100% open-source table format will soon be supported on Observe bringing vendor-neutral data processing.
Separate Compute and Storage
Observe separates storage from compute so they can be scaled independently, on-demand. This results in the most efficient utilization of resources. While compute and storage resources are physically separate, they are logically part of a single system that provides elastic, non-disruptive scaling.
Cost-efficient Cloud Object Storage
Data stored in Observe is compressed between 5 and 50x with metrics (time-series) data compressing much more than logs or traces. Once compressed, all data is stored in low cost object storage.
Always Hot Data
All data is hot, eliminating the need to create data tiers, migrate data between hot, warm and cold tiers, and deal with the toil associated with rehydrating and reindexing data. Historical data is instantly available for search and analysis.
Elastic Compute and Columnar Analytics
Compute engines scale up or down elastically to process vast amounts of data quickly and efficiently. Using parallel processing, multiple compute nodes simultaneously operate on the same data to achieve fast query performance – this scales to hundreds of nodes and thousands of cores.
Schema-On-Demand
Observe does not require data to be structured or parsed before ingestion – there are no grok scripts. Users can simply point their collector at Observe’s endpoint and benefit from fast, cost efficient ingestion. Once the data is in Observe’s data lake it can be parsed on-the-fly using schema-on-demand – either visually, through an AI-assisted UI, or using OPAL.
Data Correlation and Acceleration
Observe uniquely retains relationships between entities e.g. trace to pod to container so users can ask any question about interdependencies in their distributed system. Users can quickly drill from customers to sessions to services to metrics… and then pivot to logs or trace, all while maintaining context. Observe achieves this by transforming low level event data into structured (and related) materialized views so users can gain actionable insights much faster.
Rich and Intuitive Language
Observe Processing and Analytics Language (OPAL) offers a rich set of features and commands to search, analyze, and transform data at scale.
O11y AI
Built using Generative AI, Large Language Models (LLMs), and Agentic AI, Observe AI assists teams in quickly understanding and learning Observe. O11y Co-pilot can create OPAL queries and regexes instantly using a point-and-click UI, increasing developer productivity. AI Investigator speeds up troubleshooting and reduces time to resolution.
Try Observe Now
All your data, in one place. Ingest data from any source, in any format, and at any scale to instantly visualize performance across the entire tech stack.






